
北航计算机组成P1课下
北航计算机组成原理P1课下
通过阅读本文,你可以大致了解北京航空航天大学2023级计算机组成原理P1课下的相关内容,希望能对你有所帮助
前言
发现教程有了,不愧是STAR- 在阅读本次P1题解分享之前,我想单独分享一些关于
Verilog编写有限状态机的内容(佬跳过,好吗?好的) - 从学习完
Verilog到Pre上机之间的很长一段时间,我写Verilog有限状态机都只有一个过程块(可能大概应该有和我一样的同学吧),就像下面这样
......
module xxx (
input clk,
......
);
always@(posedge clk) begin
`S0: begin:
//状态转移代码
end
......
default: begin
//消除锁存器
end
end
endmodule- 在写一些简单的
Verilog有限状态机的时候觉得结构简单清晰易懂,怎么写这么舒服,感觉脑子都闲置了下来(bushi,但是遇到像cpu_checker_challenge那样状态多且转移方程复杂的题目,就会显得单一过程块冗长且十分不易debug,几百行代码挤在一个always块中,总感觉像写C语言只写一个main函数
- 在写一些简单的
重构Verilog结构
- 直到我遇见了
HDLbits,它向我提供了一种使用Verilog搭建和logisim结构很相似的有限状态机的代码机构,感觉会比一个always块清晰一些? - 首先,解决最大的问题,把
always块拆分出来,像logisim一样,我们将代码分出计算次态的状态转移逻辑使用纯组合电路代替reg[1: 0] state, next_state;
//时钟沿上升,状态转移
always@(posedge clk) begin
if (reset) begin
state <= 2'b0;
end else begin
state <= next_state;
end
end
//计算次态next_state
always@(*) begin
......
case(state)
`S0: begin
//状态转移
end
endcase
end
//输出逻辑方案1
always@(*) begin
out = ......
end
//输出逻辑方案2
assign out = ......- 诶呀,瞬间感觉代码变得清爽了,结构更加清晰了有没有(
没有也不许说)
- 诶呀,瞬间感觉代码变得清爽了,结构更加清晰了有没有(
- 也许此时你觉得这样不过只是拆了几个
always出来,没什么技术含量,那么接下来我们还可以利用新的结构做出一些原本结构做不出来的优化–简化代码逻辑与消除锁存器plus- 你是否常常遇到这种情况,某个变量多个状态下的变化是一致的,只有极少部分的值改变的不一致上面只展示一个状态下
always@(posedge clk) begin
case(status)
`S0: begin
if (in == a) begin
count <= 1;
.......
end else if (in == b) begin
count <= 0;
.......
end else if (in == c) begin
count <= 0;
.......
end else if (in == d) begin
count <= 0;
.......
end else begin
count <= 0;
.......
end
end
......
endcase
endcount变量的转移,如果你有10个状态呢(你真的敢像),但是如果我们使用新结构就可以在logisim一样CV吗always块开始时默认赋值了,节省代码这得益于我们使用组合逻辑的always块不是非阻塞赋值,可以多次赋值,所以不用像之前一样每个情况都要重复always@(posedge clk) begin
count <= next_count;
status <= next_status;
end
always@(*) begin
//默认赋值区域
next_count = 0;
case(status)
`S0: begin:
if (in == a) begin
next_count = 1;
.......
end else if (in == b) begin
.......
end else if (in == c) begin
.......
end else if (in == d) begin
.......
end else begin
.......
end
end
endcase
end - 同样,通过预先赋初值的办法我们就可以彻底消除锁存器这个bug了,因为锁存器产生原因就是我们没有明确赋值导致
Verilog推导出锁存器记录之前的状态(Verilog帮我们默认赋值)always@(posedge clk) begin
......
if (in == a) begin
count <= 0;
end //缺少else分支
end新结构的代码没有锁存器问题,但是不要故意不写else,重申,我们只是抑制锁存器plusalways@(*) begin
count = 0;
if (in == a) begin
count = 1;
end
end
- 你是否常常遇到这种情况,某个变量多个状态下的变化是一致的,只有极少部分的值改变的不一致
TestBench输入编写
- 我在看学长的博客之前,例如暑假学co_pre的时候我一直是使用CV编写
tb文件的。。。效率还是稍微太低了点,后来需要的测试数据加多了之后我也使用过python脚本帮我自动化生成tb文件,但是我还是不喜欢,效率还是太低了 - 于是乎,我开始寻找直接在verilog中简单编写
tb的方案,这位20级的学长提供了一个使用while循环的简单思路 - 首先我们知道
Verilog是允许给整个寄存器赋值一个字符串的reg[1023: 0] data;
reg[0: 1023] test_data;
data = "begin endBeGin this is a great End Begin end";
test_data = "begin endBgein";
// data[1023: 0](radix: ascii) ______________begin endBeGin this is a great End Begin end
// test_data[0: 1023](radix: ascii) _____________________begin endBegin - 这样字符串会按照一个字符8个bit填入data数组中,将字符串从尾部开始依次填入data尾部索引,所以我们可以通过循环取值的方式获得每一个字符
reg[0: 1023] data;
reg[1023: 0] test_data;
initial begin
// Initialize Inputs
in = 0;
data = "begin yes or no this is a question";
test_data = "begin yes or no this is a question";
// Wait 100 ns for global reset to finish
#100;
while(!data[0: 7]) data = data << 8;
while(data[0: 7]) begin
in[7: 0] = data[0: 7];
data = data << 8;
#2;
end
in = 0;
#100;
while(test_data[7: 0]) begin
in = test_data[7: 0];
test_data = test_data >> 8;
#2;
end
end
P1.Q5 表达式状态机
- 大抵是一道很显然的
Moore状态机,只需要判断需要运算符和需要数字两种状态即可,大致的思路如下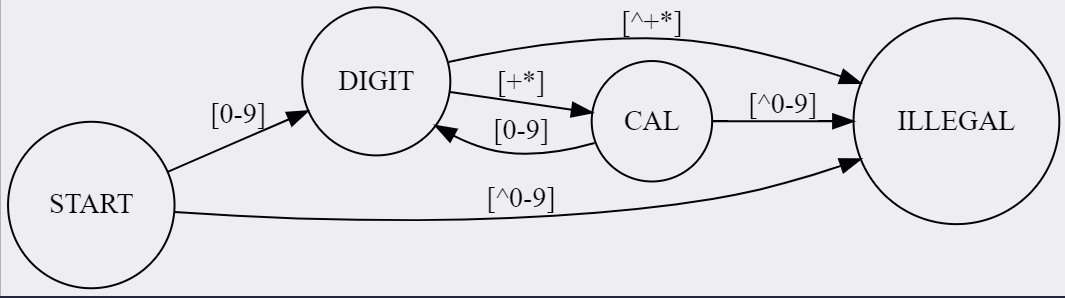
- 等等,这里的
*和正则里面的不是一个啊,这里的是\*,笔者忘改了 - 写起来也是顺手啊
- 提供一个进阶题(北航计算机组成P1推荐题汇总),移步1202-145,加入匹配括号,甚至是多重嵌套括号,思路其实是一致的
P1.extra BlockChecker
- 一道好题,
但不至于卡我一天吧(&&别再写成||了 - 因为我第一个思路因为某些莫名的原因一直没过(手真贱,所以我就换了一个思路,那么我提供两个思路思考
思路一 多个寄存器
好处是状态少,坏处是容易手误状态设置思路
- 首先设置了四个状态
start、word、illegal分别表示空闲状态、匹配单词状态、匹配已经非法状态
- 首先设置了四个状态
寄存器变量设置思路
寄存器变量 位宽 功能 num 32 保存读入的单词长度(unsigned) flag 33 保存目前未匹配的begin数量(signed) has_begin 1 前一个周期是否已经匹配begin成功 has_end 1 前一个周期是否已经匹配end成功 first 8 最近五个周期内第1个周期的字符 … 8 最近五个周期内第i个周期的字符 fifth 8 这个周期读入的in,即最近五个周期内第5个周期的字符 状态转移思路
start状态reset生效后回到start状态- 匹配到字母则
num自增,且进入状态word - 匹配到空格保持原状态
- 若匹配到其他的进入
illegal状态
word状态- 读入字母,
num自增,如果在包括此次in输入共有五个字符时,且first~fifth(in)是begin(不区分大小写),flag加1,设置has_begin - 同上,在包含此次
in共三个字符时,且third~fifth(in)是end(不区分大小写),flag减1,设置has_end - 读入字母,
has_begin已经置高,说明前面五个字符已经是begin了,但是又读入一个字母,说明这个单词不是begin了,flag减1 - 同上,
has_end已经置高了,说明这个单词不是end,flag需要加1 - 读入空格,说明单词已经读入完毕,
num置0,如果flag此时是-1(0x1ffffffff),说明先出现了未匹配的end,此时进入illegal状态,等待复位信号否则回到start空闲状态 - 读入其他字符进入
illegal状态
- 读入字母,
思路二 多个状态
好处是清晰,没有坏处- 状态设置思路
状态 描述 _start 空闲状态等待空格或者字母 _b 匹配到单词b _be 匹配到单词be _beg 匹配到单词beg _begi 匹配到单词begi _begin 匹配到单词begin _e 匹配到单词e _en 匹配到单词en _end 匹配到单词end _other 匹配到其他单词 - 寄存器设置思路
- 只需要
state寄存器保存状态和flag寄存器保存左括号数
- 只需要
- 状态转移思路
_start状态- 复位后回到
_start状态等待输入 - 如果是字母
b进入_b状态 - 如果是字母
e进入_e状态 - 如果是其他字母进入
_other状态 - 空格保持状态
- 复位后回到
_b~_en状态- 每个都是匹配到某个字母转为下一个状态:
_b匹配到字母e转到_be - 匹配到其他字母直接转为
_other - 匹配到空格回到空闲状态
- 每个都是匹配到某个字母转为下一个状态:
_begin与_end- 两个状态特殊在于判断其后是否还有字母,也即到底是完整单词还是其他单词的前缀例如
endx - 因为前一个状态转移时时默认匹配到了完整单词,例如
_begi到_begin是匹配到了begin一个周期的,所以如果后面有其他字母需要调整flag的值
- 两个状态特殊在于判断其后是否还有字母,也即到底是完整单词还是其他单词的前缀例如
_other- 接收到字母保持原态
- 接收到空格回到空闲状态
P1推荐题汇总
P1推荐题汇总本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Trash Bin for Chi!
 微信
微信 支付宝
支付宝
相关推荐



评论



