
北航计算机组成P3课下
北航计算机组成原理P3课下
通过阅读本文,你可以大致了解北京航空航天大学2023级计算机组成原理P3课下的相关内容,希望能对你有所帮助
设计文档
总要求
- 实现指令集
{addu、subu、ori、lui、lw、sw、beq、nop} - 指令集所有指令的
RTLadd(addu)
sub(subu)
ori
lui
lw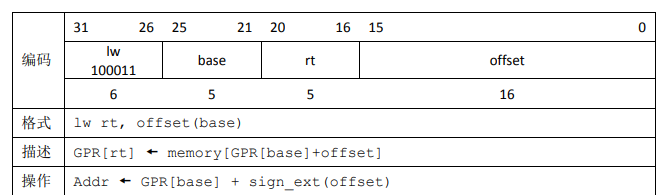

sw
beq
nop- 特殊,一般可以用
sll一起代替,这里因为指令集没有sll所以我们直接使用sll的部分代替nop
- 特殊,一般可以用
数据通路设计草图
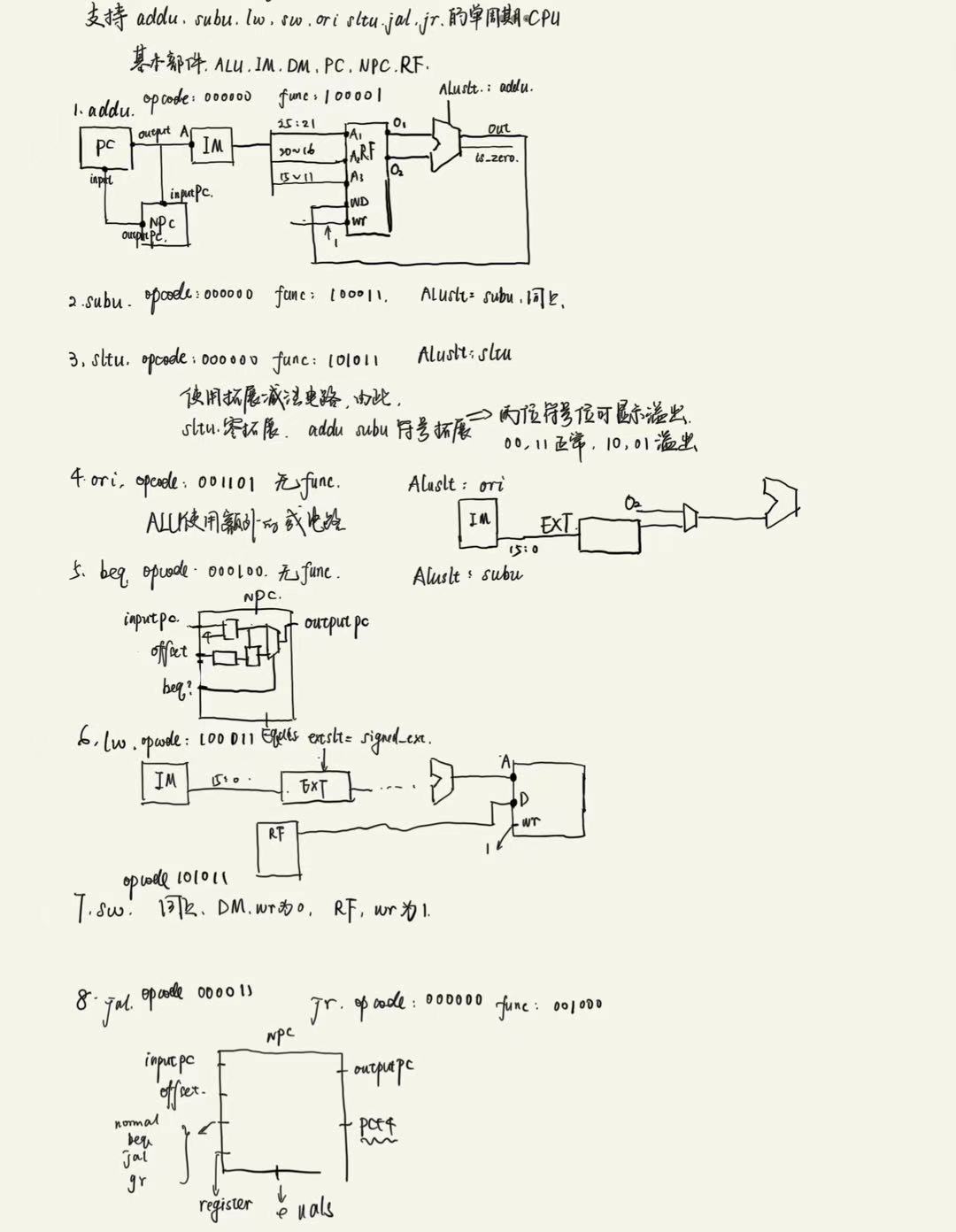
注:上述的j、jal、jr指令不在指令集中
数据通路详细设计
IF
- 首先我们观察需要设计的CPU,必不可少的一部分就是
PC、IM,没有指令谈何执行指令呢,所以我们将这个阶段称为取指(IF) - 基于低耦合的原则,我们希望
PC永远只是指向当前需要执行的指令,而不需要进行其他的操作,因此,我们在取指阶段多加入一个模块**次地址计算模块(NPC)**,专门用于计算根据PC的值以及执行的指令与结果更新PC的值 - 至此,
IF阶段的所有模块都浮出水面了分别是PC、NPC、IM
PC
- 取指阶段最最重要的一个模块无疑是
PC程序计数器,没有地址无从取指 - 程序计数器
PC始终指向当前执行的指令地址,且会根据NPC提供的值更新值端口 位宽 方向 功能描述 init[31:0] 32 input 对于PC端口的初始化,默认为 0x00003000NPC[31:0] 32 input NPC传入的值,时钟沿更新PC值 clk 1 input 时钟信号 rst 1 input 异步复位信号 PC[31:0] 32 output 当前执行的指令地址 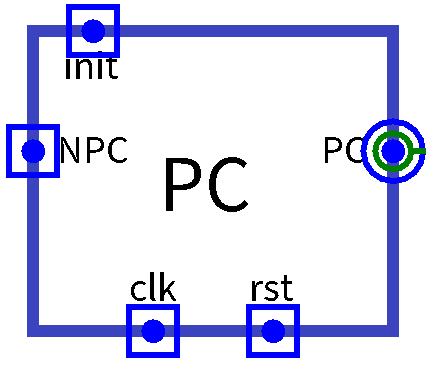
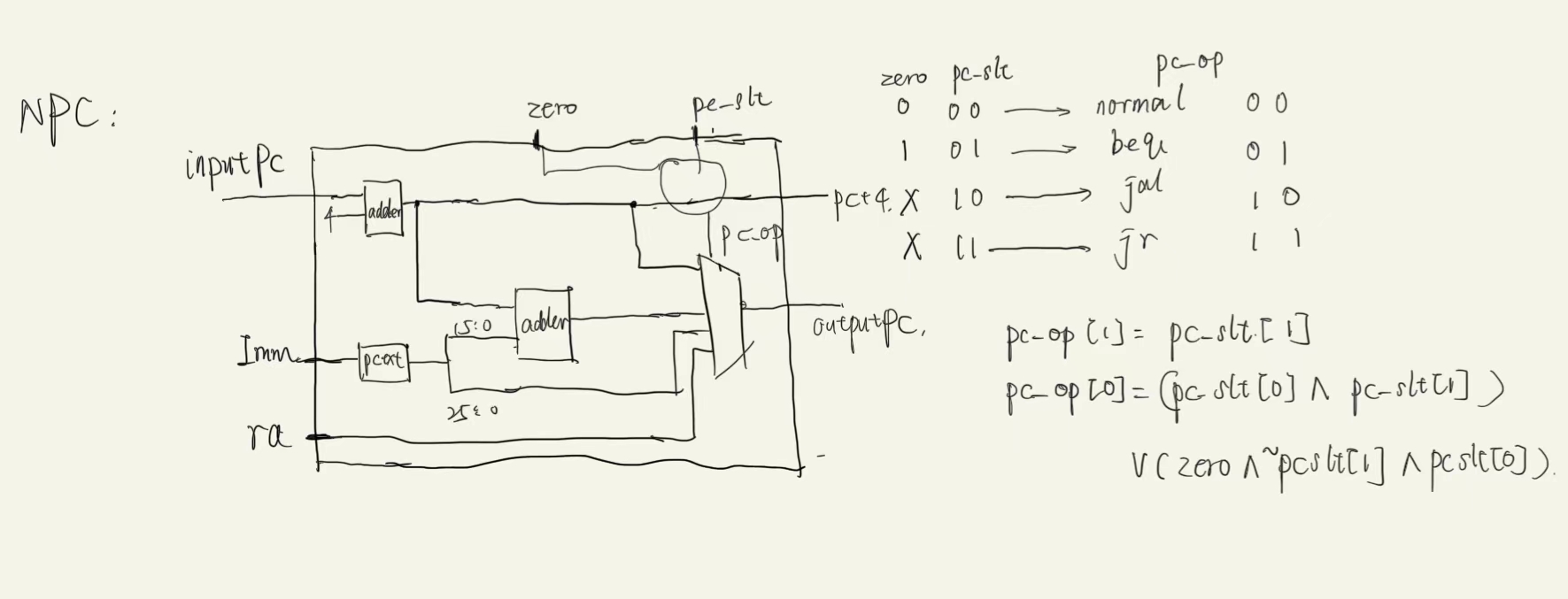
NPC
既然介绍了
PC模块,接下来就需要设计NPC模块与PC模块一起配合不断地获得需要执行的指令的地址NPC将根据当前PC的值与当前指令(例如branch类、jump类指令)综合判断更新PC的值端口 位宽 方向 功能描述 PC[31:0] 32 input 接受当前PC的值 imm[15:0] 16(目前) input branch类指令跳转的立即数 IM_slt 1(目前) input 当前执行的指令类型 RA[31:0] (暂未使用) 32 input 传递 $ra的值is_eq1(已丢弃) input 与IM_slt共同决定PC是否发生其他变化 NPC[31:0] 32 output 输出计算得到的此地址 PC+4[31:0] (暂未使用) 32 output 传递值给 jal、jalr等注意,在后续设计中
is_eq这个符号位不再传输给NPC并在NPC内部与IM_slt信号进行合并对PC值变化进行指导,而是将符号位直接传递给Controller而IM_slt表示的意思也变成了执行已满足条件的指令类型,例如1 -> beq,含义为当前指令是beq且已经满足跳转条件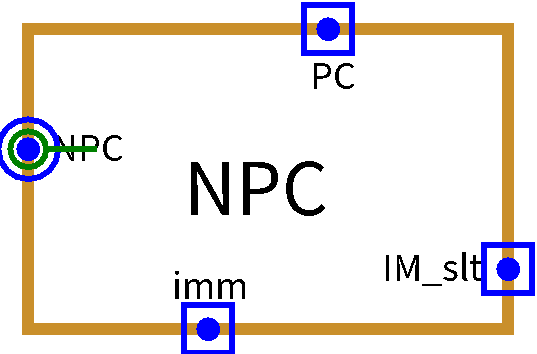
IM
- 通过
PC传入的地址寻找需要执行的地址,使用ROM存储器即可端口 位宽 方向 功能描述 PC[31:0] 32 input 传入PC的值 IM[31:0] 32 output 得到的指令 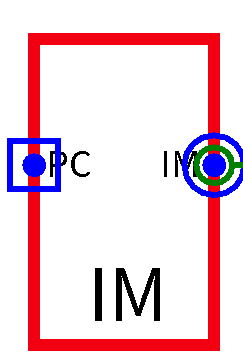
ID
- 现在我们已经可以正常地从指令存储器中取出指令了,那么为了执行指令我们首先需要明白这句指令在说什么(通过指令机器码确定指令),所以我们需要一个指令译码器
IM_SPL,其次确定了指令的类型(RIJ)、指令的含义,我们就需要取出这个指令需要的操作数因为指令的类型不同,可能来源于寄存器堆GRF,也可能来自于指令给出的立即数,所以我们需要对立即数处理的模块EXT,这个阶段称为译码(ID) - 至此,
ID阶段包含IM_SPL、GRF、EXT三个模块
IM_SPL
IM_SPL对于从IM中取出的指令进行分线器分出,通过IM_SPL的输出内容,我们能更加清晰地了解指令的类型与用途端口 位宽 方向 功能描述 IM[31:0] 32 input 传入解析的指令 opcode[5:0] 6 output 指令操作码 rs[4:0] 5 output 源寄存器 rt[4:0] 5 output 目标寄存器(J、I) rd[4:0] 5 output 目的地寄存器(R) shamt[4:0] (目前不使用) 5 output 移位 funct[5:0] 6 output 配合opcode确认R型指令 imm_i[15:0] 16 output I型指令的立即数操作数 imm_j[25:0] (目前不使用) 26 output J型指令的立即数操作数 
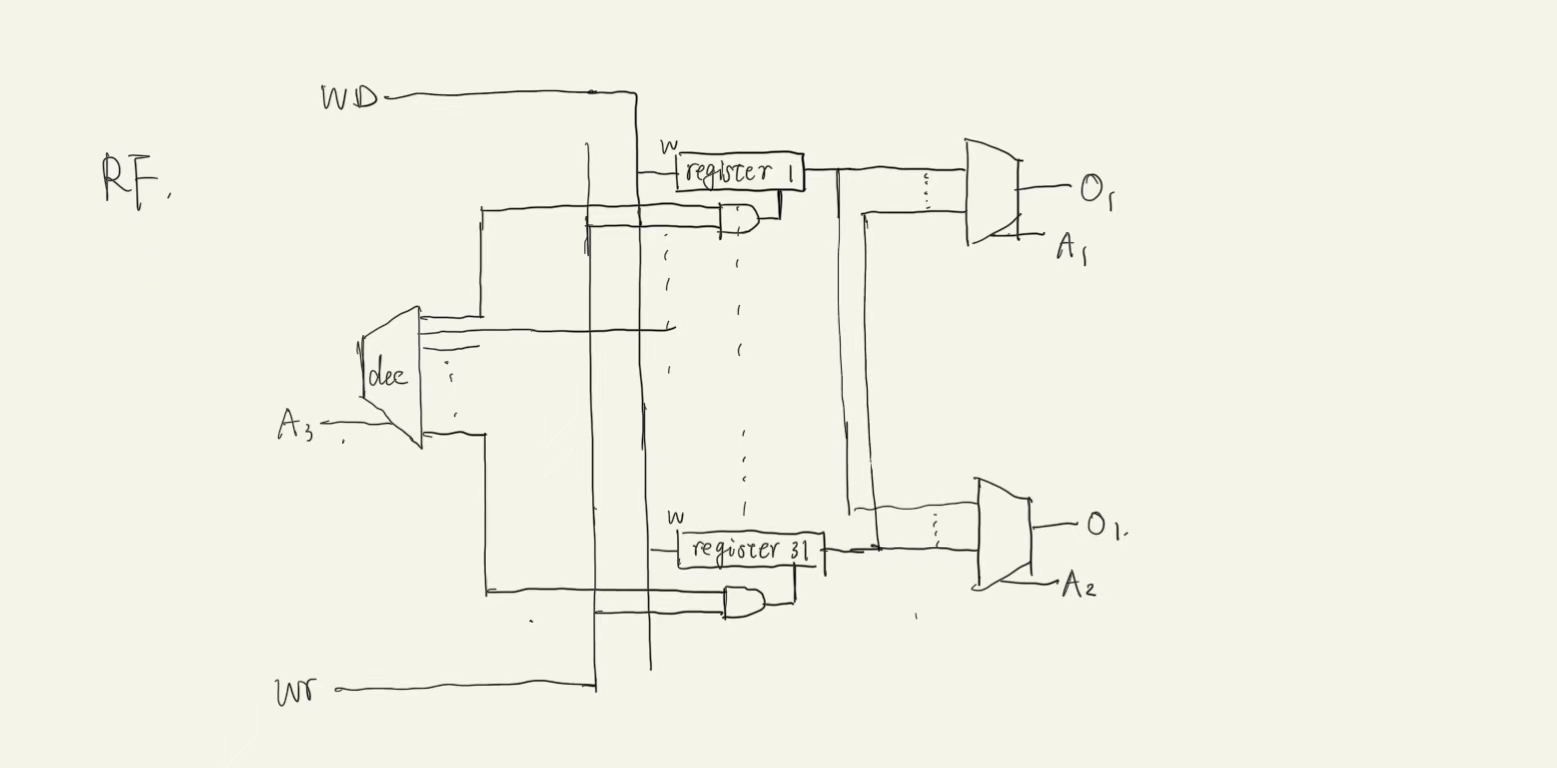
GRF
- 假设当前的是R型指令,我们需要的操作数来自于寄存器,所以我们需要使用
IM_SPL解析出来的寄存器编号去获得操作数的值端口 位宽 方向 功能描述 clk 1 input 时钟信号 rst 1 input 异步复位信号 A1[4:0] 5 input 第一个读寄存器编号 A2[4:0] 5 input 第二个读寄存器编号 A3[4:0] ( WB阶段使用)5 input 写入寄存器编号 WD[31:0] ( WB阶段使用)32 input 写入寄存器的值 WE( WB阶段使用)1 input 写使能信号 RD1[31:0] 32 output 第一个读寄存器的值 RD2[31:0] 32 output 第二个读寄存器的值 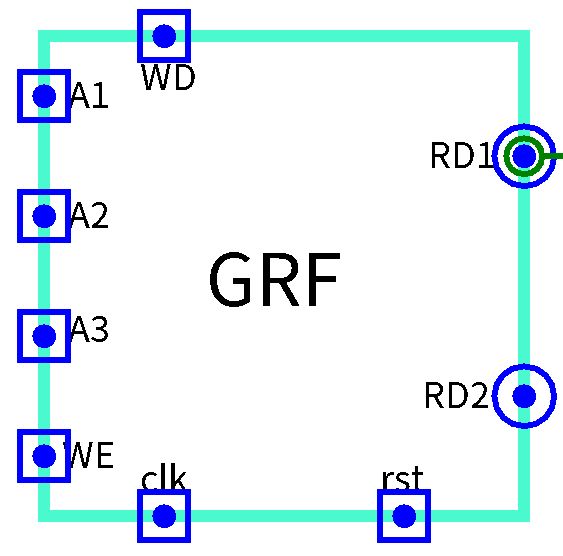
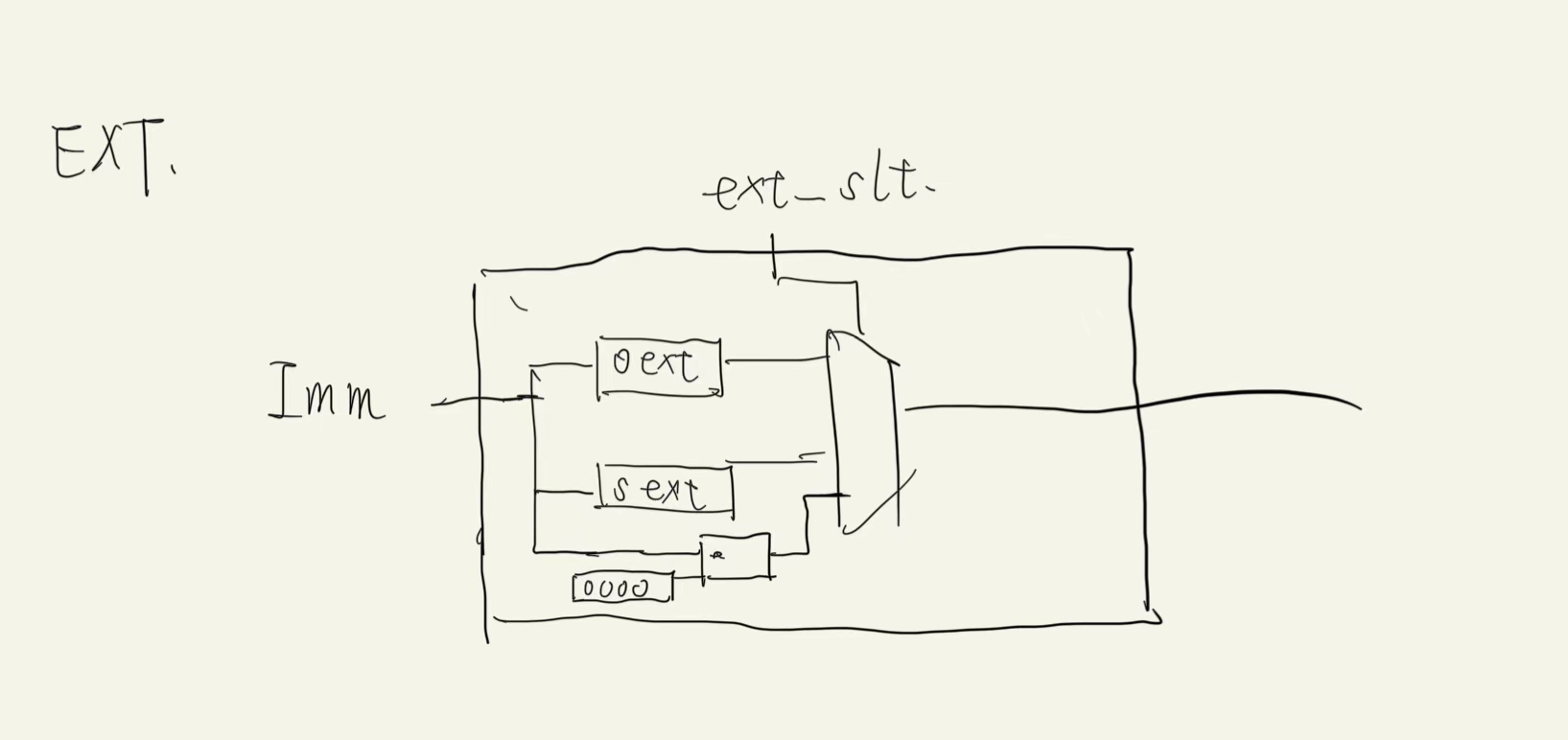
EXT
- 对于I型指令与J型指令(目前不涉及),我们虽然可以直接从指令中获得操作数,但是为了方便后续执行,我们需要将立即数位拓展至与寄存器的值的位数相同(32位),故
EXT就是根据指令来拓展立即数的模块端口 位宽 方向 功能描述 imm[15:0] 16(目前) input 指令传入的立即数 ext_slt[1:0] 2(目前) input 控制位拓展的类型 ext[31:0] 32 output 拓展后的立即数 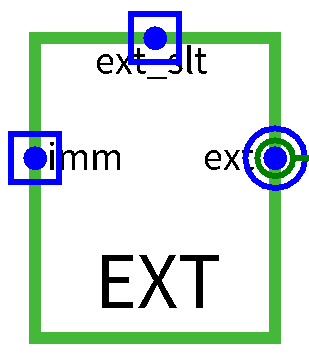
EX
- 现在我们已经做好了执行指令的前的所有准备,接下来我们对这些操作数进行某些操作得到我们指令需要内容,这个阶段称为执行(
EX) EX阶段只有一个模块ALU
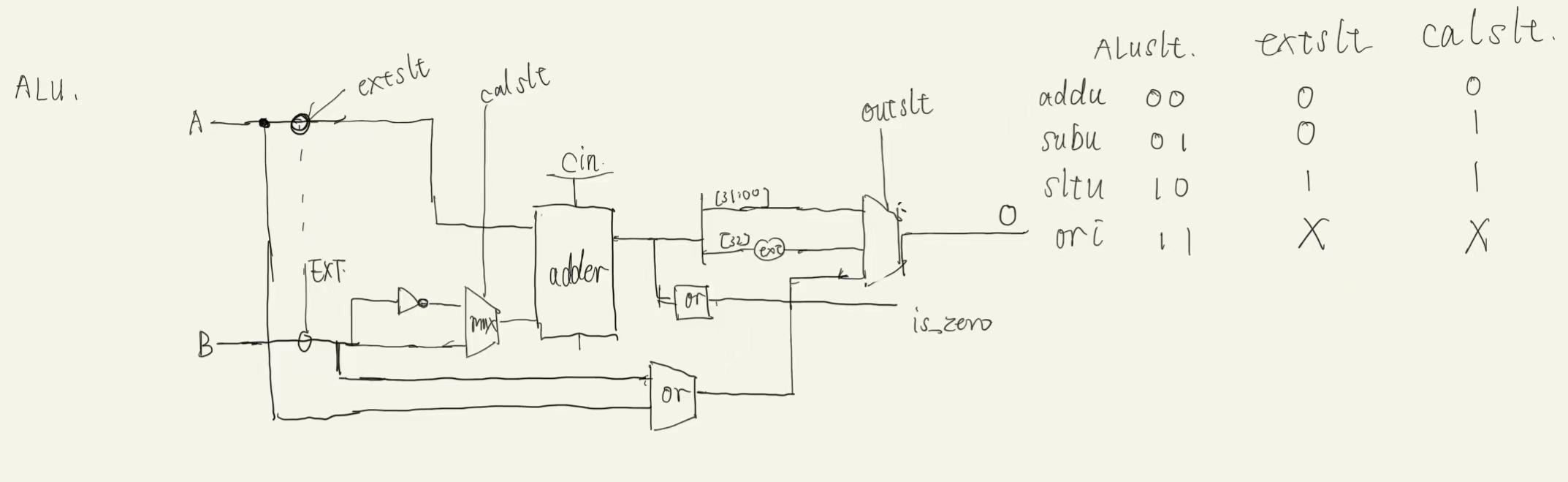
ALU
ALU算术单元来对操作数进行操作得到结果(算术类指令、逻辑类指令、存取类指令),同时通过ALU输出符号位(OFco实验不需要、ZF目前仅实现、SF比较大小需要、CFco实验不需要)端口 位宽 方向 功能描述 A[31:0] 32 input 第一个操作数 B[31:0] 32 input 第二个操作数 cal_slt 1 input 加法电路还是减法电路 out_slt[1:0] 2 input 选择输出了什么 out[31:0] 32 output 输出数据 is_eq(目前) 1 output 符号位(目前只有零信号) flag_slt(未实现) ? input 控制输出的符号位 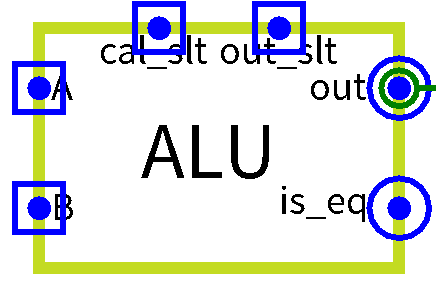
MEM
- 对于存取类指令,我们通过
EX阶段获得的是接下来需要操作数在内存中的地址,我们需要对数据存储器DM再进行相应的更改,这个阶段称为访存(MEM) MEM阶段只有一个模块DM
DM
- 存放数据的存储器,对于存取类指令,我们可以从数据存储器中取得数据
端口 位宽 方向 功能描述 clk 1 input 时钟信号 rst 1 input 异步复位信号 A[31:0] 32 input 存取数据地址 WD[31:0] 32 input 存入数据值 WE 1 input 写使能信号 RD[31:0] 32 output 读出数据值 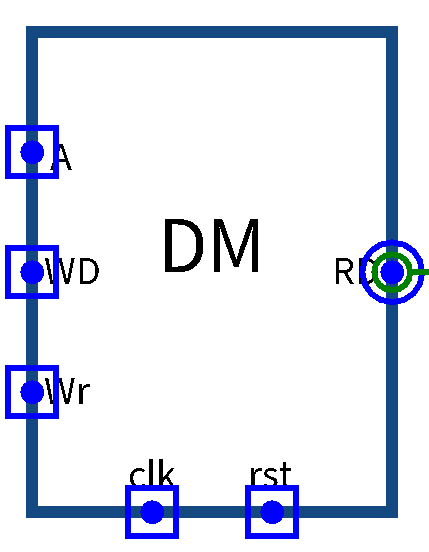
WB
- 对于
ALU计算得到的内容以及从内存中读出的值,我们经常需要写回寄存器堆,所以最后一个阶段虽然仍然是针对寄存器堆,所以这个阶段我们称其为回写(WB) WB阶段显然也只有唯一的模块GRF
GRF
- 在
ID阶段我们已经使用了GRF作为数据的提供方,但是还有一些端口没有使用,在这里我们将使用余下的一些端口
设计草图等看上面端口 位宽 方向 功能描述 clk 1 input 时钟信号 rst 1 input 异步复位信号 A1[4:0] ( ID阶段使用)5 input 第一个读寄存器编号 A2[4:0] ( ID阶段使用)5 input 第二个读寄存器编号 A3[4:0] 5 input 写入寄存器编号 WD[31:0] 32 input 写入寄存器的值 WE 1 input 写使能信号 RD1[31:0] ( ID阶段使用)32 output 第一个读寄存器的值 RD2[31:0] ( ID阶段使用)32 output 第二个读寄存器的值
总数据通路草图
- 对于单周期CPU所有基础部件我们已经搭建完毕,接下来练成数据通路只需要将相应的端口进行连接(出现多对一端口使用MUX,控制信号后面给出)
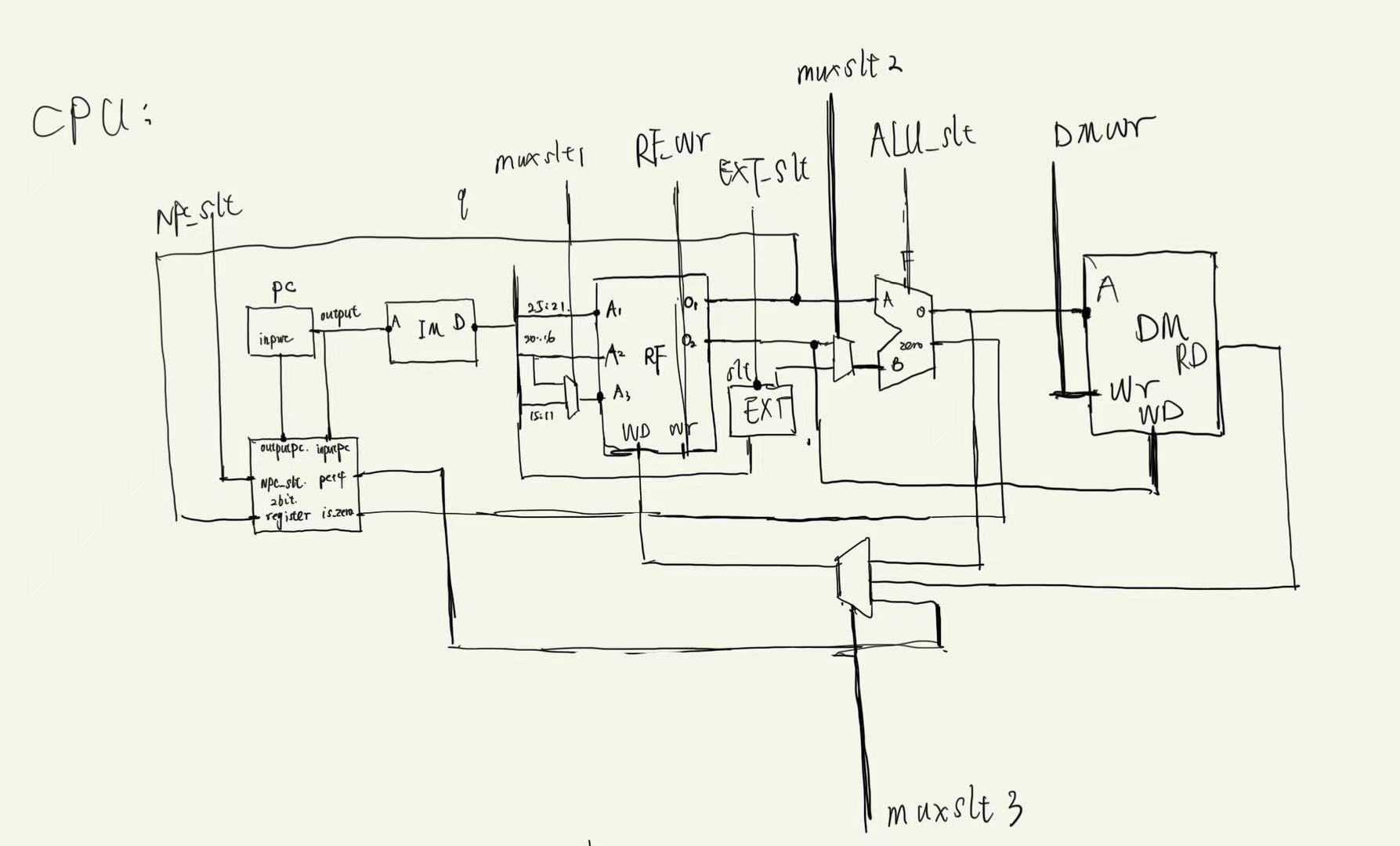
控制信号生成
在上述阶段,我们已经基本完成了各个基本指令的数据通路的实现,接下来我们将通过
Controller根据指令生成各异的控制信号来指导我们数据通路的流通接下来的所有控制信号出现顺序采用(
IF -> ID -> EX -> MEM -> WB)控制信号 位宽 功能描述 IM_slt 1 控制NPC中im_slt,说明此次执行的指令类型 A3_slt 1 控制输入GRF的A3端口,根据R型指令与I型指令不同 GRF_we 1 控制GRF的WE信号,是否写入寄存器堆 EXT_slt[1:0] 2 控制EXT的ext_slt,调整拓展指令的类型 B_slt 1 控制ALU的B端口输入,根据R型指令与I型指令不同 CAL_slt 1 控制ALU的cal_slt信号,选择加法或者减法电路 OUT_slt 2 控制ALU的out_slt信号,选择输出的类型 DM_we 1 控制DM的we信号,是否写入内存 WD_slt 1 控制GRF的WD端口输入,选择不同的写入数据 采用与或门阵列的形式生成信号,例如,先通过
opcode、funct两个信号确定执行的指令类型,再通过指令类型去生成控制信号- 与门阵列生成指令类型
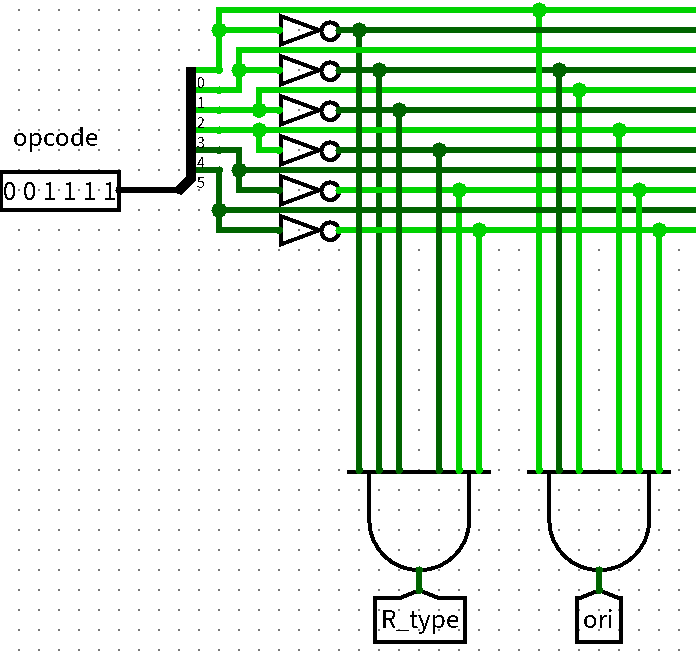
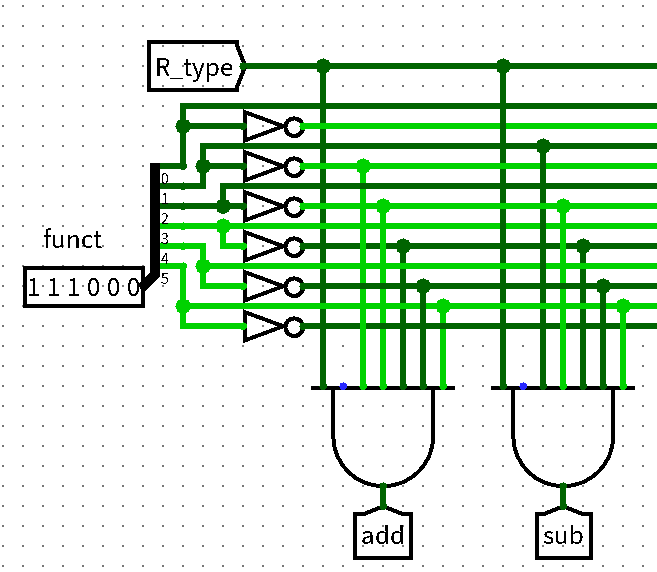
- 或门阵列生成控制信号
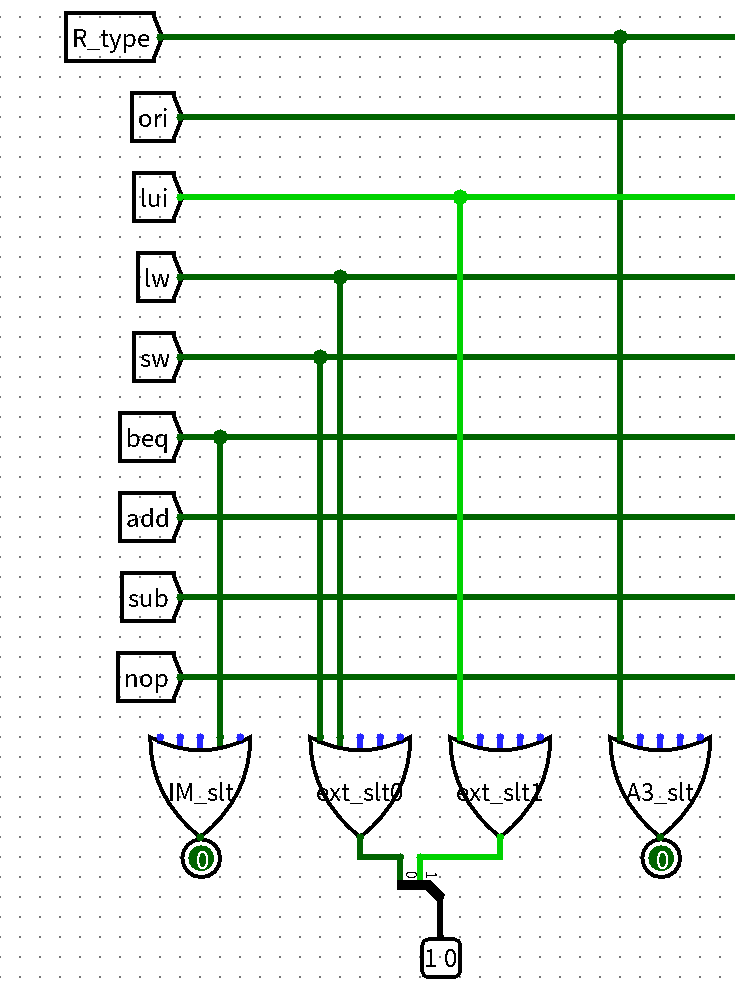
- 与门阵列生成指令类型
思考题
- 上面我们介绍了通过 FSM 理解单周期 CPU 的基本方法。请大家指出单周期 CPU 所用到的模块中,哪些发挥状态存储功能,哪些发挥状态转移功能。
CPU中的DM、GRF是状态量。通过IF、ID阶段其他部件、EX阶段的部件来实现状态转移,因为在这些阶段流通的数据并不会保存,而是随着PC的变化而变化,只有发生对DM、GRF读写才会保存下来,视为“状态的改变” - 现在我们的模块中 IM 使用 ROM, DM 使用 RAM, GRF 使用 Register,这种做法合理吗 请给出分析,若有改进意见也请一并给出。
合理,现代计算机也采取寄存器堆来保存GRF的内容,在于其访问快、效率高。对于IM存储器,我们只需要读取其中的指令而不需要改变,所以我们使用ROM是合理的;对于DM存储器,我们不仅需要从中读取数据,而且还需要向其中写入数据,所以我们使用RAM是合理的。但是他们不能使用寄存器堆,因为太浪费资源了,很多寄存器使用率太低。 - 在上述提示的模块之外,你是否在实际实现时设计了其他的模块?如果是的话,请给出介绍和设计的思路。
多设计了一个IM_SPL模块,用于将IM中取出的指令解析为{opcode, rs, rt, rd, shamt, funct, imm_i, imm_j}的格式并输出,方便后续Controller解析指令含义并生成控制信号 - 事实上,实现 nop 空指令,我们并不需要将它加入控制信号真值表,为什么?
在目前的8指令CPU中,我们通过或门阵列实现控制信号的生成,nop指令不参与任何或门,意味着全部进行默认操作,DM_we与GRF_we都为0,并不会改变CPU的状态;在后续的设计中我们知道nop实际上与sll $0, $0, 0是一致的,这个指令同样不会进行任何改变,所以完全不需要单独加入控制信号真值表中 - 阅读 Pre 的 “MIPS 指令集及汇编语言” 一节中给出的测试样例,评价其强度(可从各个指令的覆盖情况,单一指令各种行为的覆盖情况等方面分析),并指出具体的不足之处。
所有指令都没有将结果存入$0寄存器的行为,无法测试GRF的正确性add与sub没有测试边界数据如21474637等接近32位的数据,没有将$0作为操作数的情况lw与sw的base寄存器只有$0,而且offset没有同时覆盖正、负、零情况beq没有覆盖跳转且向前跳、跳转且向后跳、跳转且原地跳、不跳转且向前跳、不跳转且向后跳、不跳转且原地跳
生成测试数据
小熊正在赶制
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Trash Bin for Chi!
 微信
微信 支付宝
支付宝
相关推荐



评论



